Data Preprocessing In Orange
What is Data Preprocessing?
When we talk about data, we usually think of some large datasets with a huge number of rows and columns. While that is a likely scenario, it is not always the case — data could be in so many different forms: Structured Tables, Images, Audio files, Videos, etc..
Machines don’t understand free text, image, or video data as it is, they understand 1s and 0s. So it probably won’t be good enough if we put on a slideshow of all our images and expect our machine learning model to get trained just by that!
In any Machine Learning process, Data Preprocessing is that step in which the data gets transformed, or Encoded, to bring it to such a state that now the machine can easily parse it. In other words, the features of the data can now be easily interpreted by the algorithm.
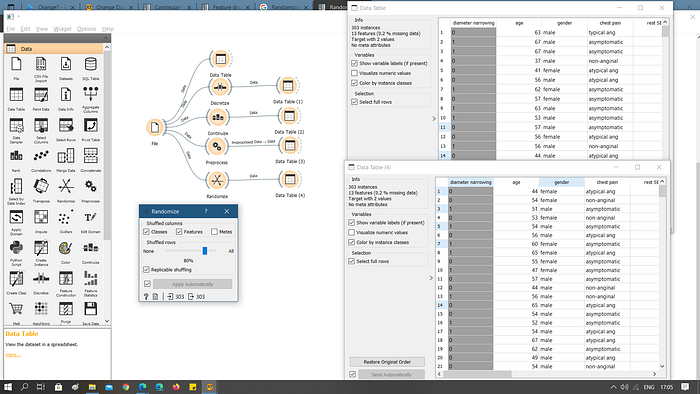
Data discretization (discretization)
Continues features in the data can be discretized using a uniform discretization method. Discretization considers only continues features, and replaces them in the new data set with corresponding categorical features:

Continuization (continuization)
Continuization refers to transformation of discrete (binary or multinominal) variables to continuous. The class described below operates on the entire domain; documentation on Orange.core.transformvalue.rst explains how to treat each variable separately.


Normalization
Normalization is the process of organizing data in a database. This includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating redundancy and inconsistent dependency.
Normalization is used to scale the data of an attribute so that it falls in a smaller range, such as -1.0 to 1.0 or 0.0 to 1.0. Normalization is generally required when we are dealing with attributes on a different scale, otherwise, it may lead to a dilution in effectiveness of an important equally important attribute


Random sampling data (Randomization)
Random sampling is done by constructing a vector of subset indices (e.g. a table of 0’s and 1’s), one corresponding to each instance, and then passing the vector to the table’s Orange.data.Table.select method.
With randomization, given a data table, the preprocessor returns a new table in which the data is shuffled. Randomize function is used from the Orange library to perform randomization.
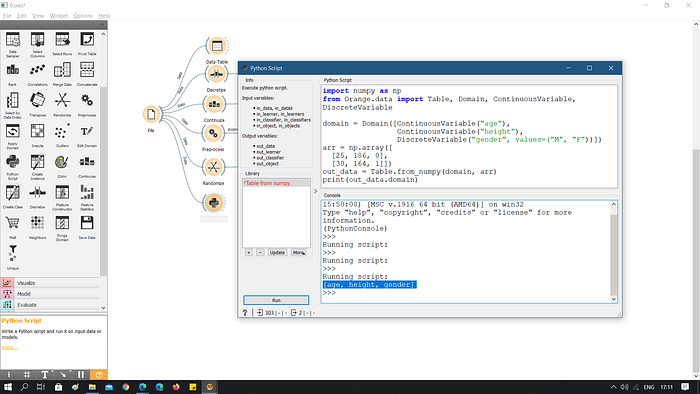
How to work with Orange in Python and vice-versa?
Python Scripts In Orange
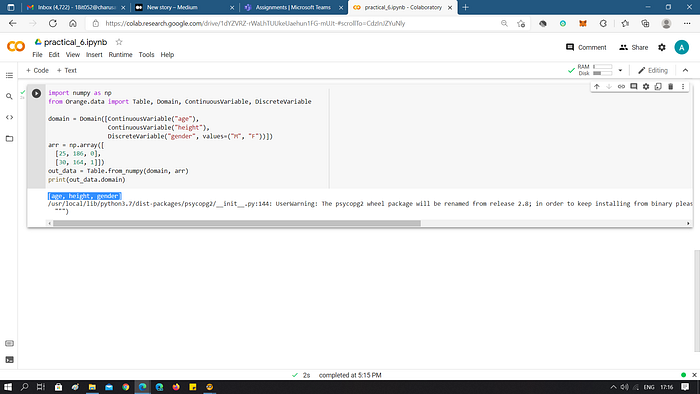
Orange in Python
Using Orange in Python is straightforward. Firstly, we have to install Orange3 in our machines using:
!pip install Orange3